时间:2025-04-18 来源:FPGA_UCY 关于我们 0
在计算技术快速迭代的今天,传统通用处理器(CPU)正逐步被专用硬件加速器补充或替代,尤其在特定计算领域。这些加速器通过针对性设计,在功耗效率、计算吞吐量(FLOPS)和内存带宽方面实现了显著优化。截至2025年4月,加速器市场需求呈指数级增长,主要驱动因素来自人工智能(AI)、机器学习(ML)、高性能计算(HPC)及边缘计算应用的广泛部署。本文将深入剖析五类主要计算加速器——GPU、FPGA、ASIC、TPU和NPU,从技术架构、性能特点、应用领域到产业生态进行系统化比较,并分析在不同应用场景下各类加速器的适用性。

硬件加速器的基本原理与关键指标
硬件加速器是专门设计用于从通用CPU卸载特定计算任务的专用处理设备,通过架构优化实现高效执行。与追求通用性的CPU不同,加速器聚焦于针对特定计算模式的并行处理能力、低延迟响应和能源效率优化。这些设备通过定制化微架构,特别适合处理具有重复性和计算密集特性的操作,如深度学习中的矩阵乘法运算或电信领域的信号处理。
评估加速器性能的关键技术指标包括:
下文将详细探讨各类加速器的技术架构、性能特性及其在实际应用中的优势。

1、图形处理单元(GPUs)技术架构与演进
图形处理单元最初设计用于图形渲染加速,但由于其高度并行的处理架构,已发展成为通用计算加速的主导平台。现代GPU集成了数千个针对单指令多数据(SIMD)操作优化的处理核心,形成了高度并行的计算矩阵,特别适合处理需要同时执行相同指令的大规模数据集。
技术规格与性能参数技术优势
GPU架构的核心优势在于其大规模并行处理能力,数千个计算核心可同时执行多线程任务,极大加速矩阵运算和向量处理。高带宽内存技术有效缓解了数据传输瓶颈,确保计算核心能够持续获得数据供给。通过CUDA、等并行计算框架,GPU实现了从专用图形处理向通用计算的扩展,支持多样化应用场景。
应用领域主要厂商与产品线与其他加速器的比较
GPU在并行计算能力和原始FLOPS性能上通常优于CPU,但在特定任务的能效比上可能不及FPGA或ASIC。其通用计算架构使其比ASIC和TPU更具灵活性,但在固定计算任务上效率相对较低。
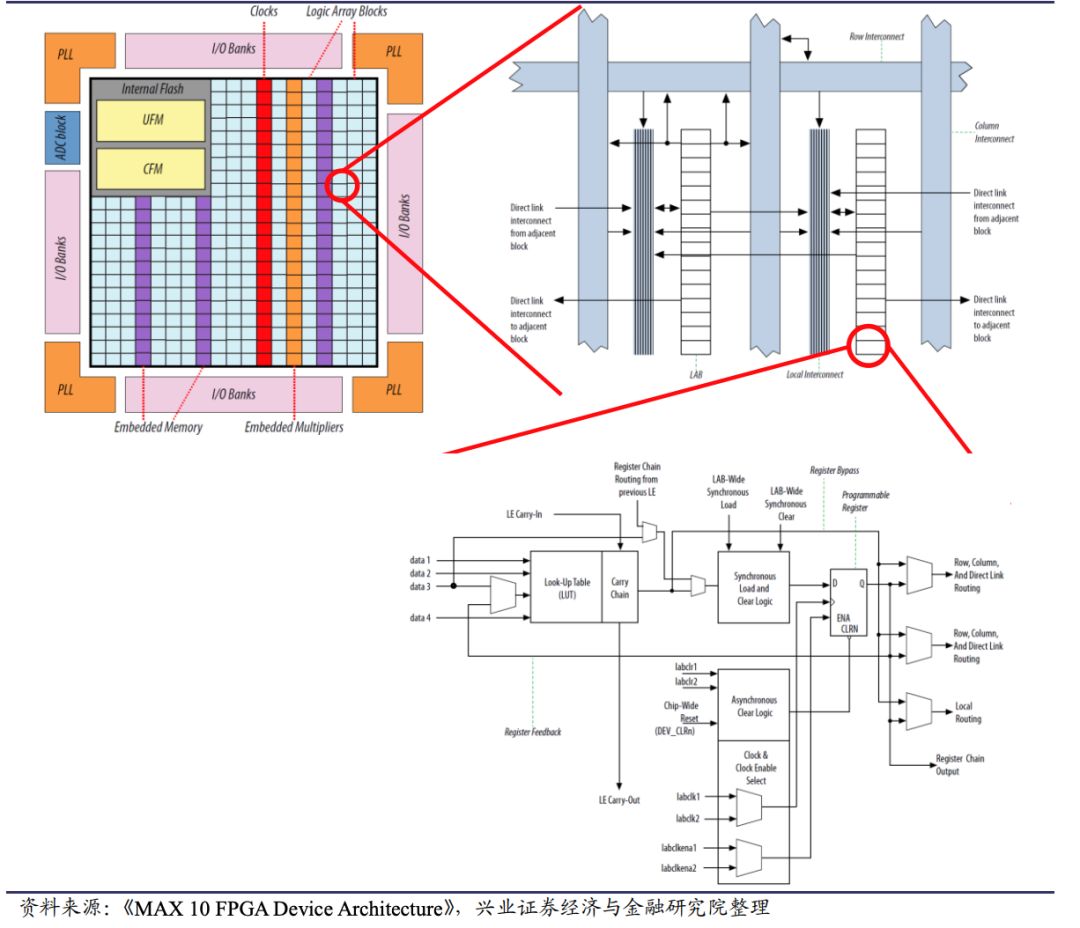
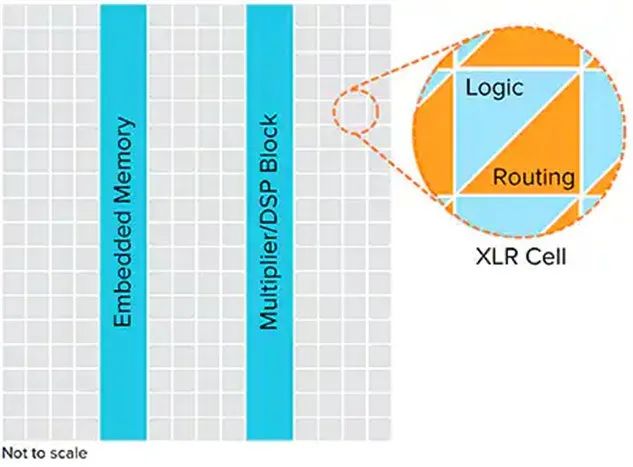
2. 可程序化逻辑门阵列(FPGAs)技术架构与特性
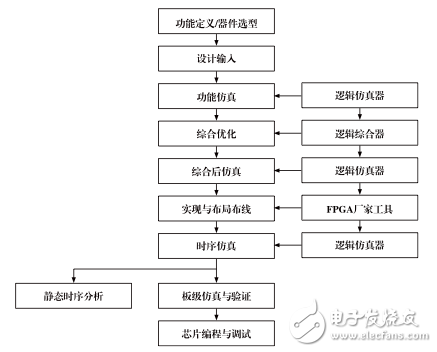
FPGA是一种可在制造后重新配置的集成电路,由可编程逻辑块、可配置互连和I/O单元组成。与固定架构的GPU不同,FPGA允许开发者根据特定算法需求定制硬件电路,提供了灵活性与性能之间的优化平衡。
技术规格与性能参数技术优势
FPGA的关键优势在于其可重配置性,允许在部署后针对新算法或工作负载进行硬件架构优化。由于可以构建定制化数据通路,FPGA在实时处理应用中表现出极低的处理延迟。同时针对特定任务优化的FPGA设计通常比通用GPU具有更高的能源效率。
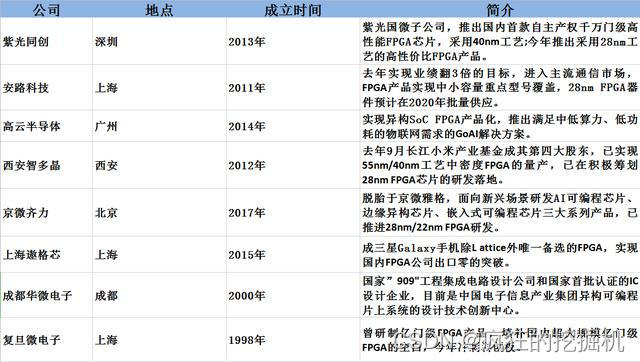
应用领域主要厂商与产品线与其他加速器的比较
FPGA在原始计算性能(FLOPS)方面通常低于GPU,但在延迟敏感和功率受限的应用环境中表现优异。与ASIC相比,FPGA对固定功能任务的能效较低但灵活性显著提高。在未集成HBM的情况下,FPGA的内存带宽通常低于高端GPU。

3、特定应用集成电路(ASICs)技术架构与设计理念
ASICs是为执行特定功能而定制设计的微处理器,其电路结构针对固定工作负载进行了优化,提供了无可比拟的执行效率。ASIC设计通过牺牲灵活性换取极致性能和能效,一旦制造完成,其功能就被固定。
技术规格与性能参数技术优势
ASIC的最大优势在于针对特定计算任务的极致优化,实现最佳的性能功耗比。集成片上内存架构减少了芯片外数据传输,显著提升了处理效率。如WSE-2等新型大规模ASIC架构可处理规模超出传统GPU能力范围的复杂工作负载。
应用领域主要厂商与产品线与其他加速器的比较
ASIC在其特定设计任务上的效率和带宽表现通常远优于GPU和FPGA,但缺乏应对算法变化的灵活性。对于通用计算任务,其原始计算性能可能低于高端GPU,而高昂的设计和生产成本限制了其应用范围,主要集中于大规模部署或特定领域应用。
4、张量处理单元(TPUs)技术架构与设计哲学
张量处理单元是开发的一类特殊ASIC,专为加速神经网络中的张量运算而设计。TPU在通用计算架构的GPU和高度专用化的ASIC之间找到了平衡点,通过对机器学习核心计算模式的优化实现高效处理。
技术规格与性能参数技术优势
TPU的核心优势在于其专为机器学习优化的矩阵乘法单元(MXU),能高效处理神经网络中的关键张量运算。TPU pod架构支持数千个处理单元的互连,实现大规模并行计算。此外,TPU与等框架的深度集成确保了软硬件协同优化。
应用领域主要厂商
作为TPU的唯一研发和生产厂商,通过Cloud TPU服务和Edge TPU产品线向市场提供TPU计算能力。
5、神经处理单元(NPUs)技术架构与设计思路
神经处理单元是为神经网络推理优化的新型专用加速器,通常集成在移动设备和边缘计算平台的系统级芯片(SoC)中。NPU设计优先考虑低功耗运行和实时推理能力,以适应资源受限环境。
技术规格与性能参数技术优势
NPU的突出优势在于其超低功耗设计,特别适合移动设备和物联网应用。其架构针对实时处理进行优化,在语音识别和图像处理等场景中表现出极低延迟。紧凑型设计允许NPU作为SoC的组成部分,有效节省空间和系统成本。
应用领域主要厂商与产品线与其他加速器的比较
NPU在功耗效率和处理延迟方面优于传统GPU和TPU,但计算能力(FLOPS)相对较低,主要针对轻量级推理而非训练任务。相比FPGA,NPU灵活性较低但针对特定神经网络运算的专业化程度更高。

加速器性能对比与选型指南能效比较
在能效方面,NPU和低功耗ASIC(如Edge TPU)以每芯片不足5W的功耗领先,这使它们成为电池供电设备和边缘计算的理想选择。相比之下,高性能GPU和大型ASIC(如WSE-2)虽然功耗较高,但针对需要极高计算密度的数据中心环境进行了优化。
计算性能比较
在原始计算能力方面,TPU和高端GPU凭借数百/TOPS的性能指标在大规模训练任务中占据主导地位。而FPGA和NPU虽然在绝对计算能力上相对较弱,但在特定任务的效率和延迟优化方面具有独特优势。
内存带宽比较
内存带宽方面, WSE-2等新型ASIC架构通过创新片上内存设计实现了拍字节级数据传输能力,重新定义了处理器内存系统的性能极限。而FPGA和NPU则依赖于相对较低带宽的内存系统,更适合数据规模较小的任务处理。
加速器选型建议GPU:当需要计算灵活性和原始计算能力时的首选。推荐 H100用于大规模AI训练,AMD 适合追求性价比的高性能计算应用。FPGA:当应用需要硬件级定制化和低延迟处理时的理想选择。 系列在边缘计算和电信领域表现尤为出色。ASIC:对于固定算法且需要极高吞吐量的工作负载,ASIC提供无与伦比的效率。 WSE-2在大规模AI研究中具有显著优势。TPU:特别适合于深度集成生态系统且需要高度可扩展性的机器学习应用场景。NPU:当功耗和尺寸约束成为首要考虑因素时,NPU是边缘设备AI推理的最佳选择。
上一篇:深圳FPGA培训课程