时间:2026-06-02 来源:FPGA_UCY 关于我们 0
一台针织大圆机正以每分钟数十转的速度织造布匹,一根断开的织针在0.1秒内掠过,留下一个即将蔓延数米的破洞。在过去,这道“瑕疵”大概率会逃过人眼,最终变成成卷的次品布。

但今天,情况不同了。在布匹离开织机前,一个基于FPGA(现场可编程门阵列) 的边缘计算系统已经完成了毫秒级的图像采集、分析和决策,触发了智能停机。这套由中国电信天翼物联推出的“AI织检云擎”,能将次布量减少80% 以上。

这不仅仅是工业质检的进步。2026年初,当英伟达发布下一代AI计算平台Vera Rubin时,一个关键变化是:首次将FPGA列为AI推理机架的标准协处理单元。这意味着,那个在纺织机旁“救火”的灵活芯片,被AI芯片霸主正式纳入了核心作战序列。
黄仁勋的这一步棋,揭示了AI算力战场一个清晰的现实:没有一种芯片能通吃所有场景,未来的胜负手在于“异构协作”。GPU、ASIC、NPU、FPGA,这四类AI加速器,正在各自不可替代的赛道上狂奔。
通用霸主GPU,为何离不开“专用队友”
你可以把GPU想象成一个超级体育馆。它拥有数万个相同的“座位”(计算核心),结构规整,擅长同时接待数万人(并行处理海量数据)。这让它成为训练千亿参数大模型的绝对主力。从2017年的V100到2024年的Blackwell,英伟达GPU的单卡推理性能提升了5倍,能耗成本降至1/25。
但体育馆的问题在于,无论来的是交响乐团还是足球赛,它都得用同一套场地和设施。当任务变成只需要几十个人完成的精密舞蹈(低延迟、特定算法推理)时,体育馆就显得大而无当,能耗偏高。
这就是ASIC(专用集成电路) 的战场。它不是为了“通用”而生,而是为特定任务量身定制的“专用工具房”。比如谷歌的TPU,其架构针对神经网络矩阵运算做了极致优化。
结果是,在类似推荐系统、视频编码这类固定算法场景下,ASIC的推理能效可以达到GPU的3倍以上,而同等算力下的成本可能只有三分之一。
如果说GPU和ASIC主要在“云端”和“数据中心”搏杀,那么NPU(神经网络处理器) 则牢牢占据了“端侧”——我们的手机、汽车和智能家居里。它的核心使命是低功耗。
联发科天玑芯片的超能效NPU,能让手机常驻的AI感知任务功耗节省42%;瑞芯微的RK3572芯片,在轻量AI任务中功耗降低50% 以上。它们让手机本地运行大模型、实时美化照片成为可能,且无需将隐私数据上传云端。

那么,被黄仁勋看中的FPGA,它的不可替代性又在哪里?
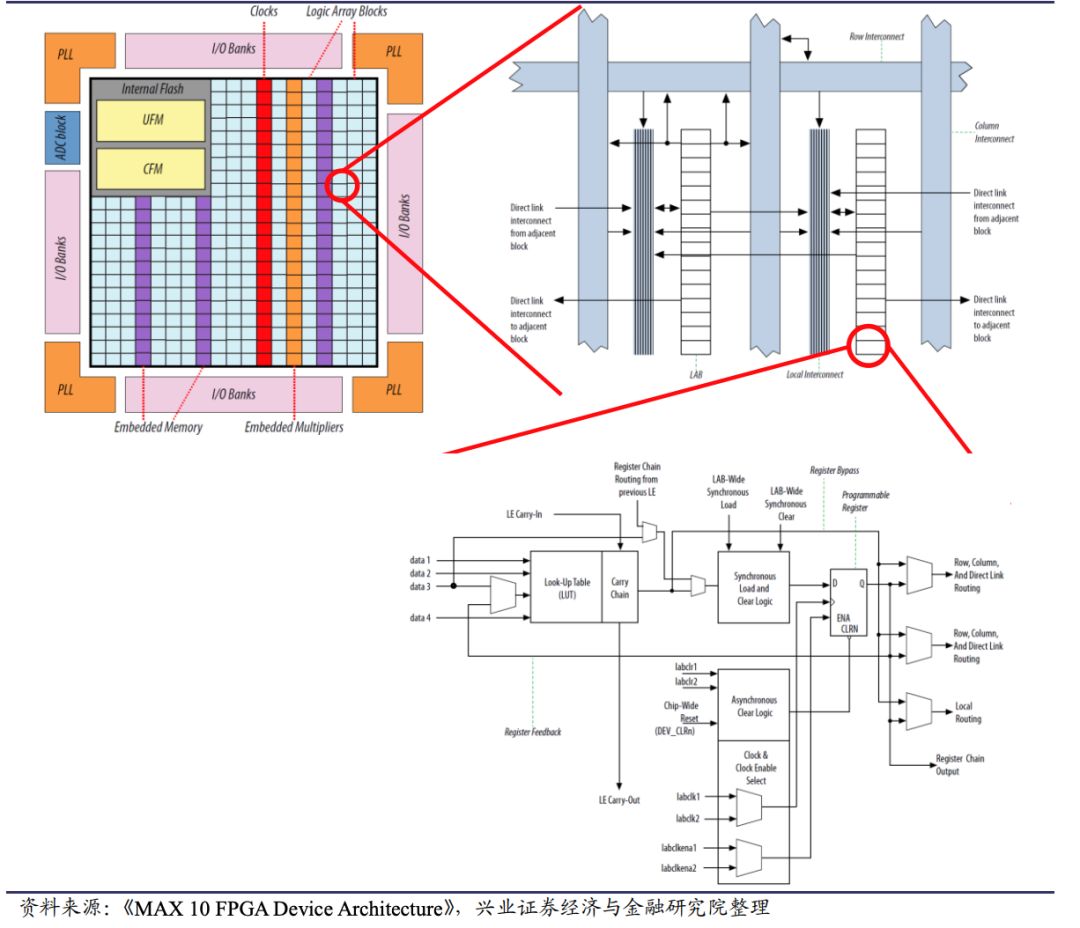
FPGA的绝活:硬件级的“变形金刚”
FPGA的本质是一块“半成品”芯片。它内部有大量可编程的逻辑单元和连线,出厂时功能是空白的,就像一盒乐高积木。开发者可以通过编程,在硬件层面将它“搭建”成任何你需要的专用电路——今天可以是图像处理器,明天刷写一下程序,就能变成信号处理器。
这带来了两个核心优势:极低的延迟和应对快速迭代的灵活性。
在纺织厂的故事里,FPGA的用武之地是“边缘”。它被部署在靠近织机的现场,直接处理摄像头传来的高速图像流。由于算法被“烧录”成了硬件电路,省去了GPU需要通过软件层调度的开销,从而实现毫秒级的检测与响应。这种“本地实时闭环”的能力,是云端GPU难以企及的。
在通信基站、工业机器人控制等场景中,协议和算法可能频繁更新。如果使用ASIC,每次更新都需要流片生产新的芯片,周期长达数月。而FPGA只需要远程推送一个新的配置文件,几秒钟内就能完成“硬件重构”。
例如在电力系统仿真中,基于FPGA的方案可以通过硬件重构快速迭代算法,提升仿真的实时性与稳定性,这是依赖固定软件栈的GPU难以做到的。
头豹研究院将这种差异概括为:GPU追求极致的通用,ASIC追求极致的效率,而FPGA追求极致的可重构。
英伟达的算力拼图,为何必须补上FPGA
理解了FPGA的独特价值,就能看懂英伟达的战略意图。随着AI应用落地,产业重心正从“训练”转向“训练+推理并重”。推理任务更加碎片化、多样化,且对成本和延迟敏感。
英伟达的Vera Rubin平台,通过配备3600GB/s的超高带宽互联,旨在将GPU、FPGA乃至其他加速器紧密连接。在这个异构体系中,GPU继续扮演通用计算和复杂训练的主力;而FPGA则被定位为“协处理器”,专门卸载那些低延迟、高并发的实时推理和预处理任务。
这形成了一个清晰的算力分工:
黄仁勋将FPGA纳入平台,并非放弃GPU的统治地位,而是构建一个更完整、无死角的算力帝国。
通过GPU+FPGA的协作,他既能继续巩固在通用AI市场的垄断(2025年训练芯片市占率超90%),又能用FPGA这把“瑞士军刀”,切入工业、通信、边缘计算等广阔而碎片化的长尾市场,抵御ASIC等专用芯片的蚕食。

最终,这场AI加速芯片的竞赛,不再是单一架构的你死我活,而是走向了“混合异构”的协同时代。每一种芯片都在自己最擅长的场景里,构建着不可替代的护城河。而谁能最有效地组织起这张异构算力网络,谁就将定义下一个AI十年的基础设施格局。